Fabric
Pool Overview
FabricPool, first
available in ONTAP 9.2, is a NetApp Data Fabric technology that enables
automated tiering of data to low-cost object storage tiers either on or off
premises. Unlike manual tiering solutions, FabricPool reduces total cost of
ownership by automating the tiering of data to lower the cost of storage. It
delivers the benefits of cloud economics by tiering to public clouds such as
Alibaba Cloud Object Storage Service, Amazon S3, Google Cloud Storage, IBM
Cloud Object Storage, and Microsoft Azure Blob Storage as well as to private
clouds such as NetApp StorageGRID®. FabricPool is transparent to applications
and allows enterprises to take advantage of cloud economics without sacrificing
performance or having to rearchitect solutions to leverage storage efficiency.
• ONTAP supports
FabricPool on AFF systems and all-SSD aggregates on FAS systems.
• ONTAP Select supports
FabricPool. NetApp recommends using all-SSD FabricPool aggregates.
NetApp
brings in an innovation in Flash storage systems, the Fabric Pool aggregates.
With FabricPool aggregates, you can move your cold data to external, less
expensive storage solutions available today.
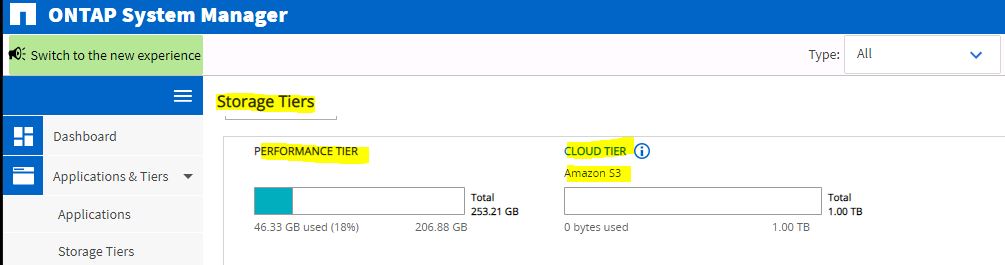
FabricPool
is an all SSD aggregate that has an external capacity tier attached to it. Data
that is written to the SSD aggregates is called as Performance tier and backup
and/or snapshots that is moved to Amazon S3 or Netapp StorageGrid Webscale is
called as Capacity Tier.
FabricPool
will be designed as an innovative technology that allows any workload (SAN or
NAS) on an ONTAP system to keep hot data on all-Flash but tier inactive cold
data off onto low-cost object storage, either on-premises or in the Cloud. This
inactive data is often up to 80% of the overall storage footprint, leading to
significant savings.
You can attach capacity tiers to SSD
aggregates and set tiering policies on the SSD volumes. Currently supported
tiering policies are:
·
Snapshot-only which is the default
· Backup – Data is tired to the
capacity tier as snapmiror/snapvault destinations
·
None
Managing FabricPool mirrors
To ensure data is accessible in data stores in the event of a disaster, and to enable you to replace a data store, you can configure a FabricPool mirror by adding a second data store to synchronously tier data to two data stores. You can add a second data store to new or existing FabricPool configurations, monitor the mirror status, display FabricPool mirror details, promote a mirror, and remove a mirror. You must be running ONTAP 9.7 or later.
Creating a FabricPool mirror
To create a FabricPool mirror, you attach two object stores to a single FabricPool. You can create a FabricPool mirror either by attaching a second object store to an existing, single object store FabricPool configuration, or you can create a new, single object store FabricPool configuration and then attach a second object store to it. You can also create FabricPool mirrors on MetroCluster configurations.
Fabric
Pool Mirroring:
To implement a fabric
pool mirror, first create a Cloud Tier (Fabric Pool) with two object stores and
attach aggregates.

Specify the amazon
account with your access key information, then provide the s3 bucket name which
you had created in amazon s3.

Once the authentication
is successful, then the cloud tier will create.
Object store created
successfully.

Using CLI, you can list
the object store configuration and the aggregates which are attached to it.
In this example, we have
one object store (aws_s3) and two aggregates (aggr1 & Aggr2) attached to
it.
Both the mirror type is
primary.


Add one more object store
(aws_s3_DR).

Now I have two object
stores (aws_s3 & aws_s3_DR).

Then you can create a
fabric pool mirror using object store mirror command.
Now you can see aws_s3 is
primary and aws_s3_DR is mirror.

You can promote the
mirror to primary also using the following command.
Now aws_s3_DR is primary
and aws_s3 is Mirror.

If you don’t want mirror,
then you can unmirror this using the following command.
Now it is unmirrored and
both are primary.

No comments:
Post a Comment